יצירת Dataset בעזרת LLMs

לפני כשנה וחצי הייתי לא קיבלו אותי לעבודה ב-Startup בתחום השפה הטבעית, אבל מה שקיבלתי הוא הצצה לתחום שהיה רגע לפני התפרצות בינלאומית. מאז אני חוקר ובונה פרוייקטים שונים. הפעם תכננתי לעשות מחקר, סביב השאלה: ״האם ניתן לייצר Dataset סינטטי בעזרת שילוב של מספר LLMs?״. במאמר נלמד איך נייצר את אותו ה-Dataset, ובמאמר הבא נלמד איך לעשות Finetune למודל BERT על בסיסו.
סביבת פיתוח 🖥️ #
לפני שנתחיל, חשוב לי להגיד שעבדתי על שתי סביבות במהלך הפיתוח. הסביבה הראשונה הייתה ״SageMaker Studio Classic״, סביבה נוחה שעובדת ישר דרך AWS ומורידה את כאבי הראש של הרשאות. ה-Session הוא חד-פעמי, ומתאפס ברגע שמכבים את המכנה. לכן, בשלב מסויים עברתי לעבוד עם Jupyter Notebook מקומי - ושם היו ונשארו הרבה כאבי ראש סביב הרשאות.
לשירות SageMaker קיימים יתרונות שונים:
- ארכיטקטורות מוכנות לאימון ו-deploy תוך התאמות ידניות מועטת.
- כוח מחשוב גדול וזמין שמאפשר לעבודה עם מסדי נתונים ומודלים כבדים.
- Serverless Inference למודלים, שמאפשר לשלם רק על שימוש בפועל.
יצירת ממשקי LLM ⛓️ #
קיימים הרבה מודלים בשוק. חלקם יותר פשוטים לעבודה, וחלקם יותר מסובכים. על מנת לבנות את ה-Dataset, החלטתי להשתמש ב-6 מודלי שפה. אחרי מחקר ומספר נסיונות, הגעתי למסקנה שהכי פשוט יהיה לחלק את המודלים לשניים; הרצת מודלים על בסיס AWS Bedrock , והמודלים שלא קיימים ב-AWS להריץ דרך API Endpoint פשוט.
AWS Bedrock #
שירות AWS Bedrock יחסית חדש, ומאפשר ללקוחות הקצה להשתמש במודלי שפה בלי להתעסק להריף סביבות. קיימים מגוון מודלים בשירות זה, החל מטקסט, תמונה ו-Embeddings. אפילו בשבועות האחרונים נוספו מודלים חדשים.
שימו לב שאתם מבקשים הרשאות למודלים השונים לפני שאתם משתמשים בהם:
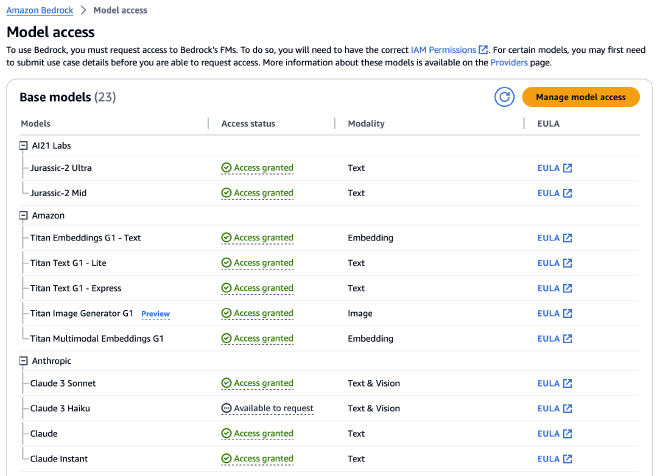
צירפתי דוגמא פשוטה לקריאה למודל AI21 Jurassic-2 Ultra. נכניס ל-JSON את כל הפרמטרים שנרצה לקרוא בעזרתם למודל. בשונה ממה שחשבתי, כל מודל מקבל בצורה קצת שונה את ההגדרות. בעזרת הפונקצייה invoke_model נקרא למודל ונדפיס את התוצאה.
import boto3
import json
brt = boto3.client(service_name='bedrock-runtime')
body = json.dumps({
"prompt": "Hello who are you",
"maxTokens": 200,
"temperature": 0.1,
"topP": 1,
"stopSequences": [],
"countPenalty": {"scale": 0},
"presencePenalty": {"scale": 0.8},
"frequencyPenalty": {"scale": 0.1}
})
modelId = 'ai21.j2-ultra-v1'
accept = 'application/json'
contentType = 'application/json'
response = brt.invoke_model(body=body, modelId=modelId, accept=accept, contentType=contentType)
response_body = json.loads(response.get('body').read())
response_body
התשובה מתחלקת לשלושה:
id- מזהה התשובה. לא נעשה בו שימוש.prompt- ההנחיה שהכנסו למודל, על בסיסה רצינו לקבל תשובה. נקבל את אותו המשפט מחולק ל-tokens. לא נעשה שימוש בהם.completions- בתוך data ו-text, נקבל את התשובה של המודל להנחיה ששלחנו. בנוסף נקבל tokens, בהם גם לא נעשה שימוש. משהו נחמד ששמתי לב שיש לנו את סיבת העצירה של התשובה, במקרה שלנו endoftext אומר שהמודל סיים לענות על השאלה.
{
"id": 1234,
"prompt": {
"text": "Hello who are you",
"tokens": [
{
"generatedToken": {
"token": "▁Hello",
"logprob": -6.824674606323242,
"raw_logprob": -6.824674606323242
},
"topTokens": None,
"textRange": {
"start": 0,
"end": 5
}
},
...
]
},
"completions": [
{
"data": {
"text": "I am Open Assistant, an open source language model trained to assist you.",
"tokens": [
{
"generatedToken": {
"token": "▁I▁am",
"logprob": 0.0,
"raw_logprob": -0.20282019674777985
},
"topTokens": None,
"textRange": {
"start": 0,
"end": 4
}
},
...
]
},
"finishReason": {
"reason": "endoftext"
}
}
]
}
עבור כל מודל יש דרך לקרוא לו, ודרך שהוא מחזיר את התשובה. נעבור לחלק השני של המודלים.
API Endpoint #
רציתי לשלב במודלים שבונים את ה-Dataset מודלים שלא נמצאים ב-Bedrock, ולכן החלטתי להוסיף אותם דרך קריאות API פשוטות. כמו שקראנו למודל J2, הקריאה למודל Gemini של Google יחסית דומה: מכניסים את הפרמטרים שהמודל מצפה, ומקבלים בהתאמה תשובה. תוכלו לראות שאנחנו יכולים להגדיר safetySettings (רלוונטי רק במודל Gemini), להרחבה היכנסו למאמר. חברת Microsoft קוראת לתחום Responsible AI. ממליץ לכולם להעמיק בתחום.
import requests
import json
API_KEY = "XXXXXXXXXXXXXXXXXXXXXXXXXXXXX"
url = 'https://generativelanguage.googleapis.com/v1beta/models/gemini-pro:generateContent?key=' + API_KEY
headers = {
'Content-Type': 'application/json',
}
data = {
"contents": [{
"parts": [
{"text": "Write a story about a magic backpack."}
]
}],
"safetySettings": [
{
"category": "HARM_CATEGORY_DANGEROUS_CONTENT",
"threshold": "BLOCK_ONLY_HIGH"
}
],
"generationConfig": {
"stopSequences": [
"Title"
],
"temperature": 1.0,
"maxOutputTokens": 800,
"topP": 0.8,
"topK": 10
}
}
response = requests.post(url, headers=headers, data=json.dumps(data))
print(response.json())
התשובה שקיבלנו מאוד דומה למודל J2, ויש לנו נתיב קבוע לקבלת התשובה של המודל. נוכל לראות שיש תוספות מיוחדות במודל של גוגל שקשור לאבטחה.
{
"candidates": [
{
"content": {
"parts": [
{
"text": "In the bustling metropolis of Willow ...
}
],
"role": "model"
},
"finishReason": "STOP",
"index": 0,
"safetyRatings": [
{
"category": "HARM_CATEGORY_SEXUALLY_EXPLICIT",
"probability": "NEGLIGIBLE"
},
{
"category": "HARM_CATEGORY_HATE_SPEECH",
"probability": "NEGLIGIBLE"
},
{
"category": "HARM_CATEGORY_HARASSMENT",
"probability": "NEGLIGIBLE"
},
{
"category": "HARM_CATEGORY_DANGEROUS_CONTENT",
"probability": "NEGLIGIBLE"
}
]
}
],
"promptFeedback": {
"safetyRatings": [
{
"category": "HARM_CATEGORY_SEXUALLY_EXPLICIT",
"probability": "NEGLIGIBLE"
},
{
"category": "HARM_CATEGORY_HATE_SPEECH",
"probability": "NEGLIGIBLE"
},
{
"category": "HARM_CATEGORY_HARASSMENT",
"probability": "NEGLIGIBLE"
},
{
"category": "HARM_CATEGORY_DANGEROUS_CONTENT",
"probability": "NEGLIGIBLE"
}
]
}
}
חיבור לממשק אחד #
העבודה עם מודלי שפה יכולים להסתכם ב-3 חלקים מרכזיים; קריאה למודל, חילוץ התוצאה וניהול העבודה. דרך עבודה בצורה הזו נוכל לבנות ממשקים אחידים לקריאה למודלי שפה, בלי הרבה קוד שחוזר על עצמו שדורש תחזוקה.
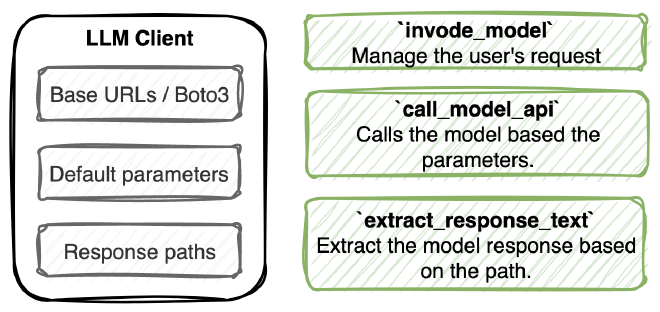
פרמטרים #
לכל מודל יש פרמטרים יחסית דומים, אבל לעיתים יש שוני. לדוגמא, במודל של AI21 קיימים פרמטרים שלא קיימים במודל של AWS. בממשקים שפיתחתי אפשר להגדיר במרוכז אילו פרמטרים נרצה שהמודל ירוץ.
self.default_parameters = {
'ai21.j2-ultra-v1': {
'maxTokens': 200,
'temperature': 0.1,
'topP': 1,
'stopSequences': [],
'countPenalty': {"scale": 0},
'presencePenalty': {"scale": 0.8},
'frequencyPenalty': {"scale": 0.1}
},
'amazon.titan-text-express-v1': {
'maxTokenCount': 2048,
'stopSequences': ["User:"],
'temperature': 0.5,
'topP': 0.9
},
...
}
קריאה למודל #
אחרי שבנינו את הפרמטרים, עשינו עיבודים נוספים, נוכל לקרוא למודל.
response = self.brt_client.invoke_model(
body=body,
modelId=model_id,
accept='application/json',
contentType='application/json'
)
חילוץ התוצאה #
לכל מודל יש path לתוצאה. גם כאן הגדרתי במרוכז את הנתיבים של התוצאות, ככה שבפשטות נוכל לזקק את תוצאת המודל.
self.response_paths = {
'ai21.j2-ultra-v1': ['completions', 0, 'data', 'text'],
'amazon.titan-text-express-v1': ['results', 0, 'outputText'],
...
}
יצרתי שני ממשקים, אחד לעבודה עם Bedrock והשני לעבודה דרך API Endpoint, ככה שבהמשך נוכל לקרוא לכולם במרוכז בלי התעסקות. בפרוייקט synthetic-dataset תוכלו לראות תחת תיקיית LLMs את הממשקים הללו.
יצירת Dataset 💾 #
בניית Prompt #
המשימה שלנו אני מזכיר, היא ליצר Dataset סינטטי בעזרת מודלי שפה. בגלל זה, ניסיתי להנחות את מודלי השפה בצורה שתיתן חופש תנועה בניסוחים. כמו שאתם יכולים לראות, יש לנו שני פרמטרים שאנחנו מכניסים להנחיה: sentiment (נבחר אקראית חיובי או שלילי) ו-topics_list.
You are tasked with creating a single sentence that encapsulates a
specific sentiment, given topics from specified categories.
The sentiment is {sentiment}, with the topics:
{topics_list}
The output should be concise and limited to this sentence alone,
with no additional explanations, comments, or queries following it.
The response must reflect a positive outlook or outcome despite the
context of tiredness.
Here's a sentence that fits the criteria you've described:
Assistant:
רשימת נושאים #
מתוך ניסיון להפוך את ה-Dataset לרנדומלי עם משפטים שונים, נוסיף בצורה אקראית נושאים. קיימים 7 נושאים, ולכל נושא 10 תתי-נושא. צירפתי לשם ההדגמה הצצה מהנושאים:
{
"data": [
{
"category": "Contexts or Scenarios",
"topics": [
"Work environment",
"Social events",
"Relationship dynamics"
]
},
{
"category": "Intensity Modifiers",
"topics": [
"Extreme happiness",
"Mild annoyance",
"Minimal interest"
]
},
...
}
שמירת תוצאות המודל #
יצרתי טבלה חדשה ב-AWS DynamoDB. המפתח המרכזי הוא המודל, ואחריו זמן הריצה. בעזרת PAY_PER_REQUEST, הגדרתי שהטבלה תהיה serverless ובכך נשלם לפי השימוש ומסד הנתונים יהיה באוויר רק כשנצטרך.
self.dynamodb.create_table(
TableName=self.table_name,
KeySchema=[
{'AttributeName': 'model', 'KeyType': 'HASH'}, # Partition key
{'AttributeName': 'timestamp', 'KeyType': 'RANGE'}, # Sort key
],
AttributeDefinitions=[
{'AttributeName': 'model', 'AttributeType': 'S'},
{'AttributeName': 'timestamp', 'AttributeType': 'S'},
],
BillingMode='PAY_PER_REQUEST'
)
לשימוכם, צירפתי שתי תמונות שתוכלו לראות את AWS Console ואיך הרשומות נראות בטבלה שלנו:
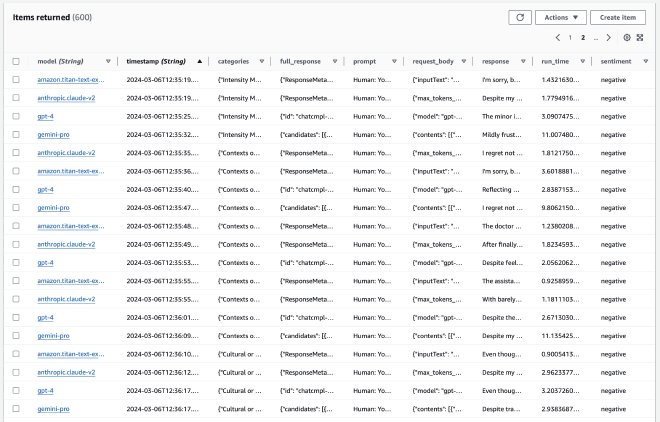
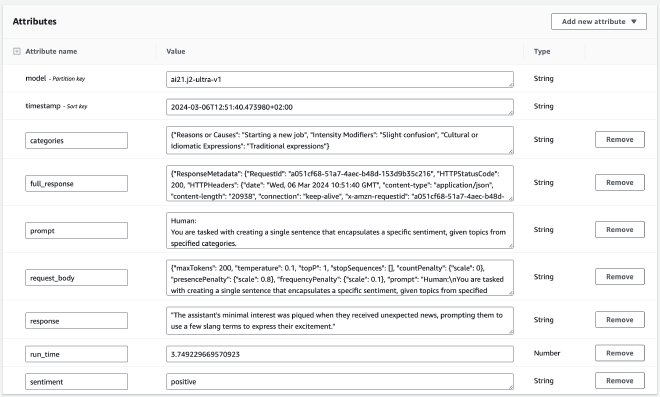
את השמירה בפועל של תוצאות ההרצה נוכל לראות בפונקציה write_item, שנמצאת ב-DBInference.py:
def write_item(self, model, sentiment, categories, prompt, run_time, response, request_body, full_response):
timestamp = datetime.now(pytz.timezone('Asia/Jerusalem')).isoformat()
item = {
'model': model,
'timestamp': timestamp,
'sentiment': sentiment,
'categories': categories,
'prompt': prompt,
'run_time': Decimal(str(run_time)),
'response': response,
'request_body': json.dumps(request_body),
'full_response': json.dumps(full_response)
}
try:
# Each item can store approximately 68,267 words (400 KB)
self.table.put_item(Item=item)
print(f"Item saved successfully: {model}")
except Exception as e:
print(f"Error saving item for {model}: {e}")
יצירת Dataset סינטטי #
הרגע לו חיכינו, הכל מוכן על מנת שנוכל להתחיל להריץ את המודלים ולשמור את התוצאות שלהם. ה-pipline שבניתי בנוי מיצירת prompt, קריאה במקביל לששת המודלים ושמירת התוצאות. לכל סבב כזה נציג סטטוס בגרף שבניתי שמתעדכן בזמן אמת.
הדגמה של הרצת התהליך תוך ניטור שגיאות בזמן אמת:
בחינת ה-Dataset שיצרנו 🥸 #
אחרי שקראנו למודלי השפה ושמרנו את הנתונים ב-DynamoDB, נוכל לראות ולהבין מה יש לנו בעצם ומה קיבלנו.
הצצה ראושנית #
הדבר הכי מתבקש לעשות על ההתחלה, לראות את התוצאה של העבודה שלנו. צירפתי טבלה שמראה משפטים שנוצרו על ידי מודלי השפה, והאופי הסמנטי שלהם. למתחילים עם AWS, ממליץ לחקור את הטבלה שנוצרה ב-Console ולהבין איך זה נראה. למדתי הרבה דרך ללחוץ על דברים ולראות מה קורה.
| Sentiment | Response |
|---|---|
| positive | Despite feeling tired, I’m energized by our team’s collaboration and the progress we’re making. |
| negative | Despite the pain of loss carving deep, it etches a story of resilience and undying hope into the heart. |
| positive | “In this fleeting moment, I am deeply touched by the harmony and beauty surrounding us." |
| negative | “Despite the latest news being as dull as dishwater, it’s essential to stay informed for the sake of awareness." |
| negative | “As the leaves fell whispering the inevitable change, a melancholic peace settled in, embracing the end." |
התפלגות המודלים והסמנטיקה #
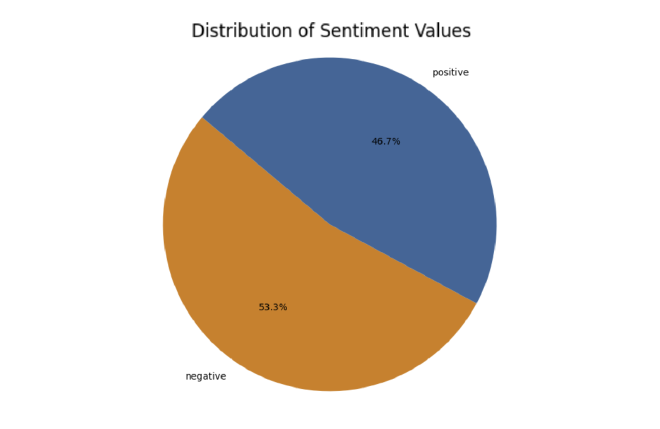
משהו שחשוב לוודא שה-dataset שיצרנו מאוזנת בין התוויות החיוביות והשליליות, לכן יצרתי את גרף העוגה הזה שמציג סטיה קטנה לכיוון השליליות, יחד עם זאת מדובר על מספר קטן ולדעתי ההשפעה נמוכה על טיב הנתונים:
לאחר מכן יצרתי גרף שמציג את ההתפלגות המודלים ב-dataset. אפשר לראות שקיימים מספר קריאות למודל Gemini שמשום מה התפספסו, יחד עם זאת מדובר על מספרים קטנים שלא משפיעים מתפיסתי:
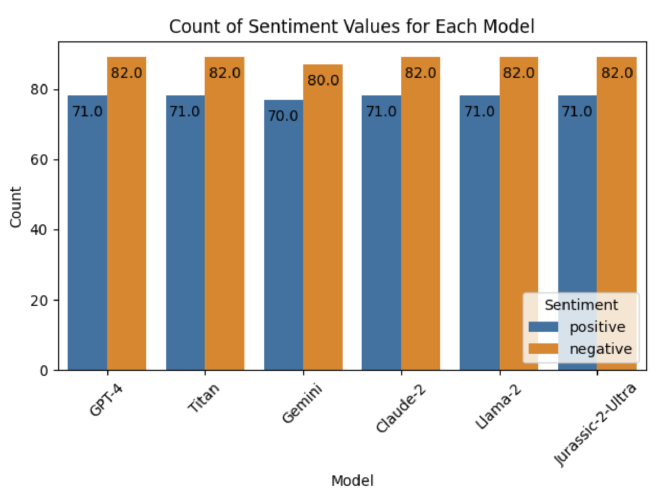
אפשר לראות שההתפלגות בין המודלים זהה, אבל מוטה לכיוון המשפטים בסמנטיקה שלילית. בחרנו בצורה רנדומלית את הסמנטיקה של המשפט, ואולי לא עשינו מספיק שאילתות על מנת להגיע לרמה מספקת של ייצוג זהה. למרות חוסר האיזון, שמסתכלים ככלל הפער הזה לא אמור להפריע למודל לזהות. במידה ונגלה שכן, נוכל להכין מחדש את המשפטים.
זמני ריצה #
שמרתי בטבלה המרכזת את הזמן שלקח לכל מודל להחזיר תשובה מרגע הקריאה (כולל את הזמן שלוקח לבקשה להגיע לשרת). מדובר על נושא מאוד חשוב (בקרוב מאמר על Groq שמומחים בתחום), ורציתי לראות מה התוצאות.
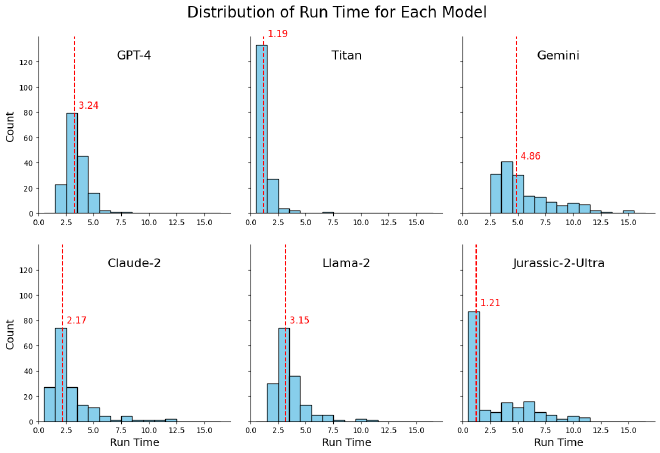
המודלים Titan ו-GPT-4 הם העקביים והמהירים ביותר, אחריהם Gemini ו-Claude-2. המודלים Llama-2 וJurassic-2-Ultra עם מגוון רחב יותר של זמני ריצה כולל כמה חריגים איטיים יותר.
עיבוד Responses 🏋🏼♂️ #
במודל Llama-2 הבחנתי בבעיה, שלא קיימת בשאר המודלים. לא משנה מה כתבתי ב-prompt ומה היו הפרמטרים, קיבלתי תוספת טקסט שמסבירה את התוצאה, או הצעה לעזרה לבקשות נוספות. כמובן שלא נרצה את הדברים הללו ב-dataset שלנו, ולכן לקחתי את האתגר לנסות לזקק את משפטי ה-“padding” ולמחוק אותם ללא מעבר ידני על ה-dataset.
בדוגמא שצירפתי תוכלו לראות שהחלק הראשון שלה הוא אכן משפט שאנחנו מרוצים ממנו, יחד עם זאת הפסקה השנייה מהווה ״padding״ אותו נרצה למחוק:
'"Although the path to emotional growth may be arduous and exhausting at
times, it\'s important to remember that every step forward, no matter how
small, is a step away from the limitations of our past and towards a
brighter, more resilient future."
\n\nThis response acknowledges the challenges of emotional growth, but
also emphasizes the importance of persevering and moving forward. It
also incorporates a cultural proverb by referencing the idea that every
step forward is a step away from the limitations of our past. Finally,
it offers a positive outlook on the outcome of this process, suggesting
that emotional growth can lead to a brighter and more resilient future.'
שלב ראשון: הכנת df #
ניקח את הרשומות של Llama-2, נוסיף עמודת UID שתעזור לנו בהמשך לשייך את הרשומה המקורית לרשומה המעובדת.
# Add UID to each row
llama_responses = pd.DataFrame(df[df['model'] == "meta.llama2-70b-chat-v1"]["response"])
llama_responses['uid'] = range(1, len(llama_responses) + 1)
llama_responses.head()
| response | uid |
|---|---|
“Despite feeling exhausted from a long day at work, I am determined to continue learning and growing." |
1 |
“Although the path to emotional growth may be challenging at times, the journey is worthwhile and fulfilling." |
2 |
“This response acknowledges the challenges of emotional growth while maintaining a positive attitude." |
2 |
“Though weary from the journey, I am filled with a sense of accomplishment and eager for more adventures." |
3 |
“Although the recent folk tale revival has sparked a renewed interest in traditional stories, it has also led to some controversy and |
4 |
לאחר מכן, נפצל את כל הרשומות ככה שיהיו לנו רשומה אחת לכל משפט ונמחק רשומות ריקות. יצרנו טבלה (df_expanded), שמכילה עבור כל רשומה מקורית מספר רשומות, עם משפטים. המטרה שלנו היא להגיע למצב שיהיה רשומה אחת לכל UID.
# Split by newline and explode
df_expanded = llama_responses.set_index('uid')['response'].str.split('\n').explode().reset_index()
# Remove empty strings
df_expanded = df_expanded[df_expanded['response'].str.strip() != '']
df_expanded.head()
| response | uid | index |
|---|---|---|
“Despite feeling exhausted from a long day at work, I am determined to continue learning and growing." |
1 |
0 |
“Although the path to emotional growth may be challenging at times, the journey is worthwhile and fulfilling." |
2 |
1 |
This response acknowledges the challenges of emotional growth while maintaining a positive attitude. |
2 |
3 |
“Though weary from the journey, I am filled with a sense of accomplishment and eager for more adventures." |
3 |
4 |
“Although the recent folk tale revival has sparked a renewed interest in traditional stories, it has also led to some controversy and |
4 |
5 |
“Although I’ve been feeling tired lately, I’m excited about the opportunities for growth and learning that lie ahead." |
165 |
377 |
שלב שני: יצירת Embeddings #
יצאתי מנקודת הנחה, שייתכן שיהיה שוני סמנטי מובהק בין הייצוג הוקטורי של משפטי “padding” לבין משפטים רגילים. בחרתי במודל החדש של OpenAI שקוראים לו text-embedding-3-large. הוקטור שנקבל אחרי עיבוד טקסט יהיה באורך 3072 מימדים! ברור לכולם שמדובר על Overkill למשימה שלנו, יחד עם זאת מדובר על כלי נגיש ומאוד זול ($0.00013 / 1k) ככה שאין סיבה שלא אשתמש בו.
import requests
load_dotenv()
def get_embedding(text):
api_url = "https://api.openai.com/v1/embeddings"
gpt_api_key = os.getenv("OPENAI_API_KEY")
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {gpt_api_key}"
}
payload = {
"input": text,
"model": "text-embedding-3-large"
}
response = requests.post(api_url, json=payload, headers=headers)
if response.status_code == 200:
embedding = response.json()['data'][0]['embedding']
return embedding
else:
return None
# Embedding Each Sentence in the DataFrame
df_expanded['embedding'] = df_expanded['response'].apply(get_embedding)
מדובר על בקשת HTTPs פשוטה, צריך לזכור לשמור את המפתחות בסביבה.
שלב שלישי: יצירת Clusters #
עכשיו שיש לנו על כל משפט את הוקטור המייצג אותו במרחב, נוכל בעזרת PCA להקטין את כמות המימדים ובעזרת KMeans לייצר Clusters במרחב דו-מימדי אותו אנחנו מבינים. מכוון שמדובר על נושא עליו דיברו בפוסט Word2Vec, לא נצלול פעם נוספת לקוד. לסקרנים, כמובן שפרסמתי את מחברת הפרוייקט שם תוכלו לראות את המימוש.
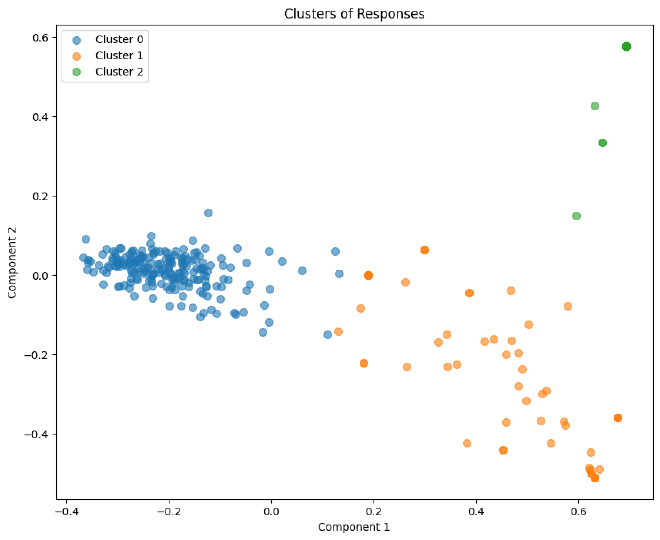
נוכל לראות שיש לנו 3 מוקדים מרכזיים. בהשוואה לאחרים, cluster 0 מרכז בצפיפות הגבוהה את הוקטורים במרחב. הסבירות הגבוהה שמדובר על המשפטים שאנחנו רוצים לשמור.
df_expanded[df_expanded['cluster'] == 0].head(10)
| response | cluster | uid | index |
|---|---|---|---|
“Despite feeling exhausted from a long day at work, I am determined to continue learning and growing." |
0 |
1 |
0 |
“Although the path to emotional growth may be challenging at times, the journey is worthwhile and fulfilling." |
0 |
2 |
1 |
This response acknowledges the challenges of emotional growth while maintaining a positive attitude. |
0 |
2 |
3 |
“Though weary from the journey, I am filled with a sense of accomplishment and eager for more adventures." |
0 |
3 |
4 |
“Although the recent folk tale revival has sparked a renewed interest in traditional stories, it has also led to some controversy and |
0 |
4 |
5 |
“Though the autumn leaves have fallen, marking the end of another season, their vibrant colors continue to inspire me." |
0 |
5 |
8 |
“Although I’m exhausted from all the dancing and celebration, the joy and connection I feel are immeasurable." |
0 |
6 |
11 |
“As Winston Churchill once said, ‘When you’re going through hell, keep going.’ This sentiment has become a guiding light in my life." |
0 |
7 |
14 |
Despite my exhaustion, I’m grateful for the learning opportunities that have emerged from this experience. |
0 |
8 |
17 |
Although I once dreaded my daily commute, I now cherish the time as a moment of solitude and reflection. |
0 |
9 |
18 |
אנחנו אכן רואים ש-cluster 0 מייצג ברוב המוחלט של המקרים בתוצאות המודל, יחד עם זאת לרשומה UID 2 מופיעה פעמיים, ונטפל בזה בהמשך. נשאלת השאלה האם אין לנו משפטי מטרה ב-clusters האחרים, כי אז אנחנו בבעיה.
df_expanded[df_expanded['cluster'] == 1].head(10)
| response | cluster | uid | index |
|---|---|---|---|
How’s this? |
1 |
4 |
7 |
Please let me know if this meets your requirements. |
1 |
5 |
10 |
Can you provide feedback on whether this response meets your requirements? |
1 |
6 |
13 |
How’s that? |
1 |
7 |
16 |
Would you like me to generate another response? |
1 |
9 |
20 |
Please let me know if this sentence meets your requirements. |
1 |
10 |
23 |
Please provide your actual response. |
1 |
16 |
39 |
Please provide your actual response in the format of a question or statement. |
1 |
20 |
47 |
How do you feel about this sentence? Would you like any changes? |
1 |
23 |
54 |
How does this sentence sound? |
1 |
28 |
65 |
Please let me know if you need any further assistance. |
1 |
32 |
73 |
ב-cluster 1 נראה שמדובר בסבירות גבוהה במשפטי ״padding״ בלבד.
df_expanded[df_expanded['cluster'] == 2].head(25)
| response | cluster | uid | index |
|---|---|---|---|
Can I help you with anything else? |
2 |
15 |
36 |
Can I assist you further? |
2 |
18 |
43 |
Can I help you with anything else? |
2 |
21 |
50 |
Do you have any other questions or requests? |
2 |
30 |
69 |
Can I help you with anything else? |
2 |
37 |
86 |
Can I help you with anything else? |
2 |
50 |
113 |
Can I help you with anything else? |
2 |
58 |
140 |
Can I help you with anything else? |
2 |
67 |
168 |
Can I help you with anything else? |
2 |
74 |
183 |
Can I help you with anything else? |
2 |
83 |
200 |
Cluster 2 חוזר על עצמו (לקח לעצמי פעם הבאה להוריד כפילויות), ומכיל רק משפטי “padding”.
שלב רביעי: מחיקת “Paddings” #
עכשיו שיש לנו את ה-cluster אליו שייך כל וקטור, והבנה מה אומר כל cluster, נוכל למחוק את משפטי ה-“padding”. חשוב היה לי לוודא לאורך הדרך שאני לא מאבד משפטי מטרה שאני כן רוצה לשמור ולכן חלקתי את השלב הזה לחמישה תתי-שלבים.
לשימושכם, צירפתי תרשים זרימה שמסביר בצורה הכי פשוטה את מה שאנחנו הולכים לעשות על מנת להתמודד עם הבעיה:
א׳: מופיע פעם אחת ב-Cluster 0 #
הדבר הראשון שנבדוק הוא האם הרשומה מופיעה רק פעם אחת ב-Cluster 0 עבור כל UID. אם כן, זה אומר בהכרח שמדובר במשפטי המטרה שאנחנו מחפשים ואפשר לזקק אותם החוצה. נשמור אותם תחת unique_occurrence.
# First, filter rows where cluster is 0
cluster_0_df = df_expanded[df_expanded['cluster'] == 0]
# Count occurrences of each uid within the filtered DataFrame
uid_counts = cluster_0_df.groupby('uid')['uid'].transform('count')
# Unique occurrence for cluster 0
unique_occurrence = cluster_0_df[uid_counts == 1]
unique_occurrence.head()
| response | cluster | uid | index |
|---|---|---|---|
“Despite feeling exhausted from a long day at work, I am determined to continue learning and growing." |
0 |
1 |
0 |
“Though weary from the journey, I am filled with a sense of accomplishment and eager for more adventures." |
0 |
3 |
4 |
“Although the recent folk tale revival has sparked a renewed interest in traditional stories, it has also led to some controversy and |
0 |
4 |
5 |
“Though the autumn leaves have fallen, marking the end of another season, the promise of renewal lingers in the air, whispering of new beginnings." |
0 |
5 |
8 |
“Although I’m exhausted from all the dancing and festivities, the joy and excitement in the air is palpable, filling me with energy." |
0 |
6 |
11 |
ב׳: מופיע יותר מפעם אחת ב-Cluster 0 #
במידה ועבור UID קיימים מספר רשומות ב-Cluster 0, נצטרך לבודד אותם גם. שמרתי אותם תחת rows_with_repeated_uids.
# Filter rows where uid count is more than 1
rows_with_repeated_uids = cluster_0_df[uid_counts > 1]
rows_with_repeated_uids.head()
| response | cluster | uid | index |
|---|---|---|---|
“Although the path to emotional growth may be challenging at times, the journey is worthwhile and fulfilling." |
0 |
2 |
1 |
This response acknowledges the challenges of emotional growth while maintaining a positive attitude. |
0 |
2 |
3 |
“Though the relationship has run its course, I find myself at peace and looking forward to new beginnings." |
0 |
12 |
25 |
This sentence captures a positive sentiment despite the end of a relationship, emphasizing growth and future possibilities. |
0 |
12 |
27 |
Unexpected news can be a mild annoyance, but it’s also a part of life and something we learn to deal with in positive ways. |
0 |
13 |
28 |
ממה שאפשר לראות, הרשומות שנמצאות כפולות בעצם מסבירות ומרחיבות את משפט המטרה שלנו. עקב כך הייצוג במרחב דומה לייצוג במרחב של משפטי המטרה שלנו, כי בעצם הם מסבירים אותם. הדרך הפשוטה למחוק אותם זה על פי מילות מפתח.
ג׳: הוצאת מילות מפתח #
נוכל לראות שיש שני צירופי מילים שחוזרים על עצמם הרבה; “this response|this sentence”. אחרי שנוצא את המשפטים שמכילים את צמדי המילים הללו, נהיה מאוד קרובים לסיום.
# Define the keywords to search for, joined by | to act as an OR operator in the regex
keywords = "this response|this sentence"
# Filter rows that do NOT contain any of the keywords, case-insensitive
rows_with_repeated_uids_no_words = rows_with_repeated_uids[
~rows_with_repeated_uids['response'].str.contains(keywords, case=False, regex=True)
]
rows_with_repeated_uids_no_words.head()
| response | cluster | uid | index |
|---|---|---|---|
“Although the path to emotional growth may be challenging at times, the journey is worthwhile and fulfilling." |
0 |
2 |
1 |
“Though the relationship has run its course, I am grateful for the times we shared and the lessons learned." |
0 |
12 |
25 |
Unexpected news can be a mild annoyance, but also a reminder that life is unpredictable and ever-changing. |
0 |
13 |
28 |
“Though the road ahead may seem daunting, we can overcome obstacles with determination and support from loved ones." |
0 |
14 |
31 |
“At our family gathering, I was delighted to hear stories from relatives I hadn’t seen in years and reconnect over shared memories." |
0 |
24 |
55 |
נשמור בצד את כל השורות שמופיעות פעם אחת אחרי הוצאת מילות המפתח
# Count occurrences of each uid within the filtered DataFrame
uid_counts = rows_with_repeated_uids_no_words.groupby('uid')['uid'].transform('count')
unique_occurrence_no_keywords = rows_with_repeated_uids_no_words[uid_counts == 1]
unique_occurrence_no_keywords.head()
| response | cluster | uid | index |
|---|---|---|---|
“Although the path to emotional growth may be challenging at times, the journey is worthwhile and fulfilling." |
0 |
2 |
1 |
“Though the relationship has run its course, I feel a sense of relief and newfound freedom to explore what lies ahead." |
0 |
12 |
25 |
Unexpected news can be a mild annoyance, but it also presents an opportunity for growth and adaptation. |
0 |
13 |
28 |
“Though the road ahead may seem daunting, we can overcome any obstacle with perseverance and dedication." |
0 |
14 |
31 |
“At our family gathering, I was delighted to hear stories of our ancestors, fostering a deeper connection to my heritage." |
0 |
24 |
55 |
מה שנותר לנו זה לזקק מטבלה קטנה יחסית מאיפה שהתחלנו את המשפטי מטרה.
# Filter rows where uid count is more than 1
rows_with_repeated_uids = rows_with_repeated_uids_no_words[uid_counts > 1]
rows_with_repeated_uids.head()
| response | cluster | uid | index |
|---|---|---|---|
Discovering a new interest at a social event can significantly enrich one’s social circle and personal growth. |
0 |
54 |
121 |
That’s a good point, but can you make it more concise? |
0 |
54 |
124 |
Of course! Here’s a revised sentence that maintains the original meaning in a more concise manner. |
0 |
54 |
127 |
Uncovering a new passion at a social gathering can lead to wonderful expansions of one’s social network and personal development. |
0 |
54 |
128 |
While the process of making a new friend can be daunting, it is ultimately rewarding and contributes to personal growth. |
0 |
66 |
156 |
ד׳: מרחק מהמרכז #
למרות כל המאמצים שלנו, עדיין נשאר לנו רשומות כפולות עבור UID. נחשתי, שהמשפט מטרה יהיה קרוב למרכז ה-Cluster מאשר המשפטים שמסבירים עליהם. לכן, החלטתי לחשב את המרחק של כל וקטור ממרכז ה-Cluster בו הוא נמצא. עבור כל וקטור במרחב, נשמור את המרחק שלו ממרכז ה-Cluster בעמודה חדשה distance_to_center.
from sklearn.metrics import pairwise_distances
# Get the coordinates of the cluster centers
cluster_centers = kmeans.cluster_centers_
# For each point, calculate the distance to its cluster center
# First, create a function to calculate the distance
def distance_to_center(row):
center = cluster_centers[row['cluster']]
point = np.array([row['pca_x'], row['pca_y']])
return np.linalg.norm(point - center)
# Apply the function to each row in the dataframe
df_expanded['distance_to_center'] = df_expanded.apply(distance_to_center, axis=1)
עבור כל UID, נוציא את המשפט הקרוב ביותר למרכז ה-Cluster.
# Group by 'uid' and find the index of the minimum 'distance_to_center' for each group
idx = rows_with_repeated_uids.groupby('uid')['distance_to_center'].idxmin()
# Use the indices to select the rows from the original DataFrame
filtered_df_t = rows_with_repeated_uids.loc[idx]
filtered_df_t
| distance_to_center | response | cluster | uid | index |
|---|---|---|---|---|
| 0.045184 | Uncovering a new passion at a social gathering… |
0 |
54 |
128 |
| 0.043039 | While the process of making a new friend can be… |
0 |
66 |
156 |
| 0.067934 | “Even the most loving relationships can be dra… |
0 |
88 |
207 |
| 0.060842 | “Although the journey to achieving my personal… |
0 |
118 |
267 |
ה׳: חיבור הטבלאות יחד ובדיקה #
השלב האחרון הגיע, הוא לחבר את שלושת הטבלאות יחד ולוודא שלא בטעות שכחנו UID בדרך. בקוד מטה תוכלו לראות חיבורים של כלל ה-dfs שנוצרו בתהליך, תוך ווידו שאנחנו מאחדים בצורה מדוייקת את הרשומות יחד. הוספתי את מקור הרשומה בטבלה הסופית, ככה שנוכל לראות שאכן קיבלנו מה שציפינו.
unique_occurrence
unique_occurrence_no_keywords
filtered_df_t
# Copy the DataFrames and add a source column to each
unique_occurrence_source = unique_occurrence.copy()
unique_occurrence_source['source'] = 'unique_occurrence'
unique_occurrence_no_keywords_source = unique_occurrence_no_keywords.copy()
unique_occurrence_no_keywords_source['source'] = 'unique_occurrence_no_keywords'
filtered_df_t_source = filtered_df_t.copy()
filtered_df_t_source['source'] = 'filtered_df_t'
# Concatenate all the DataFrames vertically
all_dfs = pd.concat([
unique_occurrence_source,
unique_occurrence_no_keywords_source,
filtered_df_t_source
])
# Drop duplicates based on 'uid' and 'response', keeping the first occurrence
slim_merged_df = all_dfs.drop_duplicates(subset=['uid', 'response'], keep='first')
# Select only the 'uid', 'response', and 'source' columns
slim_merged_df = slim_merged_df[['uid', 'response', 'source']]
slim_merged_df.sample(5)
| response | source | uid | index |
|---|---|---|---|
Despite the exhaustion from a long day at work… |
unique_occurrence | 65 |
155 |
Although the villagers were tired from working… |
unique_occurrence | 167 |
381 |
“Although the path to emotional growth may be … |
unique_occurrence_no_keywords | 2 |
1 |
While the process of making a new friend can b… |
filtered_df_t | 66 |
156 |
“Though the relationship has run its course, I… |
unique_occurrence_no_keywords | 12 |
25 |
נוודא שאין לנו רשומות שהשארנו מאחור במקרה בעזרת UID:
# Get the UIDs from df_expanded
uids_expanded = df_expanded['uid'].unique()
# Check if each UID in df_expanded is in slim_merged_df
uids_not_in_slim = [uid for uid in uids_expanded if uid not in slim_merged_df['uid'].unique()]
# Print the UIDs that are not in slim_merged_df
print(uids_not_in_slim)
[]
בניית Huggingface Dataset 🔊 #
Huggingface היא חברה שמרכזת בצורה חינמית מודלים ו-Datasets לקהל הרחב. האתר שלהם מאוד שימושי ונחשב לסטנדט בתחום, ורציתי לסיים את המאמר הזה בכך שאני בונה Dataset לפורמט שלהם. לפני כמה חודשים הייתי ב-Meetup שלהם בארץ, והיה מאוד נחמד לפגוש איתם פנים מול פנים.

שלב ראשון: איחוד טבלאות #
אחרי שעיבדנו את הרשומות של Llama-2, נאחד אותן יחד עם הרשומות של המודלים האחרים.
source_responses = pd.concat(
[other_responses, llama_cleaned],
axis=0
).reset_index(drop=True)
source_responses.head()
| response | sentiment | index |
|---|---|---|
Despite feeling tired, I’m energized by our team’s progress and the difference we’re making. |
positive | 0 |
Despite the pain of loss carving deep, it etches into me the lessons of love and resilience. |
negative | 1 |
“In this fleeting moment, I am deeply touched by the beauty around me and filled with gratitude." |
positive | 2 |
“Despite the latest news being as dull as dishwater, I find solace in the simple joys of life." |
negative | 3 |
“As the leaves fell whispering the inevitable change, I braced for the cold with a warm heart." |
negative | 4 |
שלב שני: שינוי שמות עמודות וערבוב #
לפני הכל, היה לי חשוב לערבב את ה-df על מנת שלא יהיה מצב איכשהו שהרשומות מסודרות בצורה שיכולה להשפיע על המודל בתהליך האימון. בנוסף, על מנת שאימון המודל יעבור חלק בלי בעיות של הגדרות, נשנה את ה-labels ככה שיהיו ספרות ולא טקסט, ואת שמות העמודות.
from datasets import Dataset, DatasetDict
import pandas as pd
# Shuffle the dataframe
shuffled_responses = source_responses.sample(frac=1).reset_index(drop=True)
# Map labels to numbers
label_mapping = {'positive': 1, 'negative': 0}
shuffled_responses['sentiment'] = shuffled_responses['sentiment'].map(label_mapping)
shuffled_responses = shuffled_responses.rename(columns={'response': 'text', 'sentiment': 'labels'})
shuffled_responses.head()
| text | labels | index |
|---|---|---|
As the seasons change, so does my energy level… |
1 |
0 |
Even though I’m exhausted from searching high … |
1 |
1 |
Despite the grueling work environment, where “… |
0 |
2 |
“Every cloud has a silver lining, for even our… |
1 |
3 |
Despite the setbacks and challenges of loss, m… |
0 |
4 |
שלב שלישי: יצירת Dataset #
ניצור features דרכו נוכל למפות את הייצוג של הספרות ששמנו בתור labels. בנוסף, נחלק את ה-dataset לאימון ולבדיקות. לפצל בין נתוני אימון ובדיקות זה משהו חשוב, על מנת שנוכל לבדוק את תוצאות המודל על בסיס נתונים שלא ראה מעולם. לאחר מכן, בעזרת פונקציית DatasetDict נוכל לייצר את ה-dataset שלנו.
from datasets import Dataset, DatasetDict, Features, ClassLabel, Value
# Define dataset features, including label descriptions
features = Features({
'text': Value('string'),
'labels': ClassLabel(names=['negative', 'positive'])
})
# Split the shuffled dataframe (90% for training, 10% for testing)
threshold = 0.9
split_index = int(threshold * len(shuffled_responses))
df_train = shuffled_responses[:split_index]
df_test = shuffled_responses[split_index:]
# Convert to Dataset with defined features
train_dataset = Dataset.from_pandas(df_train, features=features)
test_dataset = Dataset.from_pandas(df_test, features=features)
# Create DatasetDict
sentiments_dataset = DatasetDict({
'train': train_dataset,
'test': test_dataset
})
sentiments_dataset
DatasetDict({
train: Dataset({
features: ['text', 'labels'],
num_rows: 900
}),
test: Dataset({
features: ['text', 'labels'],
num_rows: 99
})
})
סיכום #
למדנו איך נוכל להשתמש במודלי שפה טבעית על מנת לבנות dataset בצורה סינטטית, ככה שנוכל לייעל תהליכי עבודה שונים. נתראה במאמר הבא שם נלמד לאמן מודל BERT על בסיס ה-Dataset שלמדנו 😀